Spring Batch — Introduction
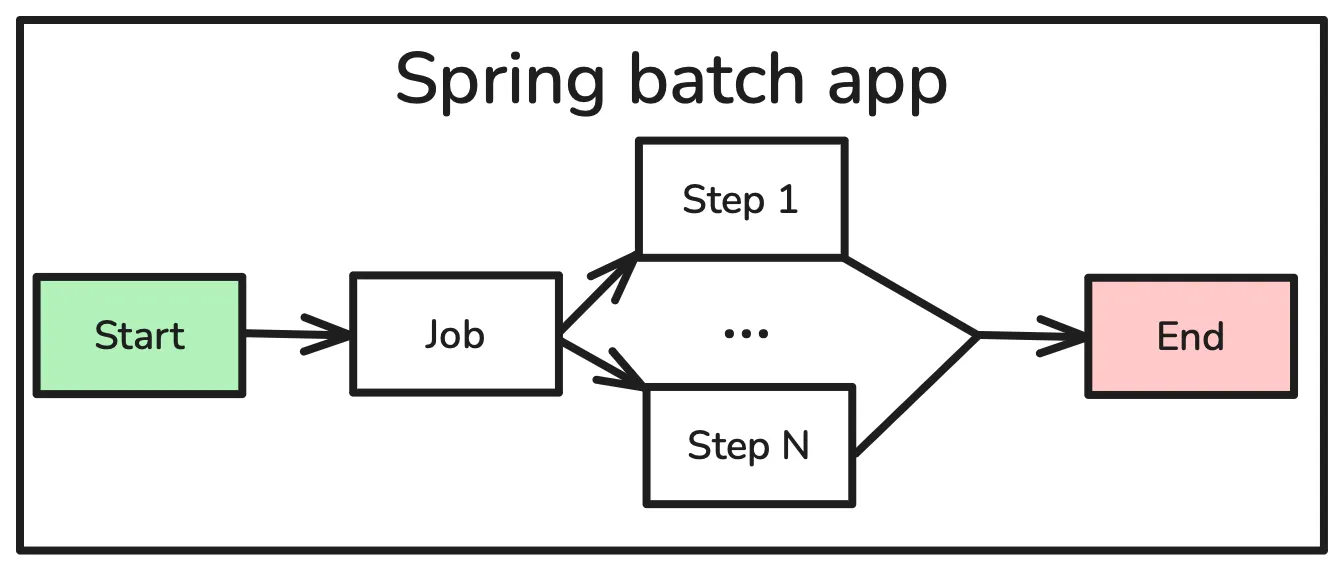
What is Spring Batch?
It is a framework within the Spring ecosystem designed for building robust, scalable, and high-performance batch processing applications in Java.
A Spring Batch application consists of the execution of a scheduled job which is made up of steps. These steps can be chunk-oriented —with a reader, a processor, and a writer— or a tasklet step, to implement logic that doesn’t fit the chunk-oriented architecture.
Chunk-oriented step
The most common way to take advantage of all the benefits of processing large datasets with Spring Batch is to use chunk-oriented steps. These can be built with a reader and a writer, but it is also possible to set a processor in the middle.
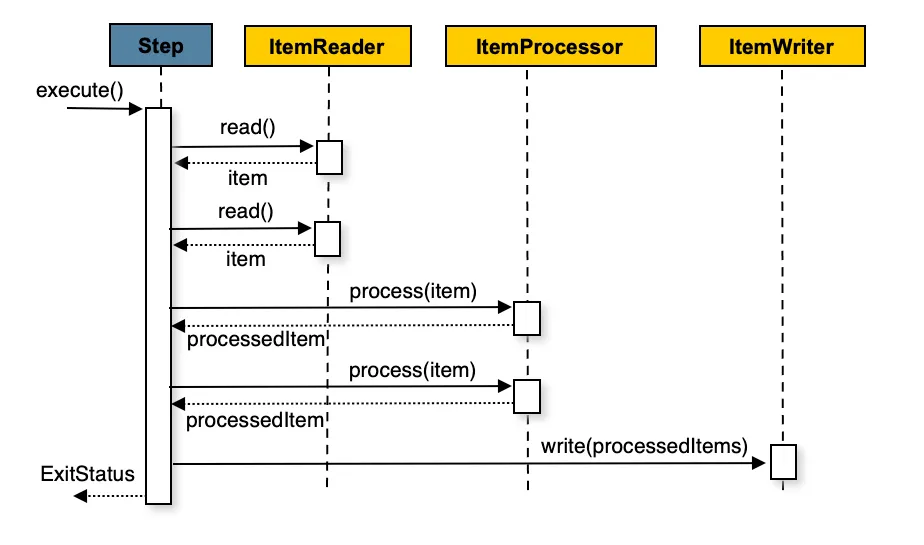
Reader
It is responsible for reading the information to be processed in our step. Spring Batch offers some default classes to read different data formats like flat files, JSON, XML, JDBC, JPA, Mongo, and Kafka.
Processor
As the image above shows, it is intended to apply any transformation or business logic to the item before writing it. If, while processing, it is determined that the item is not valid, returning null indicates that the item should not be written out.
Writer
The writer is responsible for taking the transformed items and writing them to the desired output (database, flat file, queue). It receives the data in chunks and writes them in bulk, improving performance and reducing resource usage.
Chunk
A group of items that are read, processed, and written together as a single unit within a step. Chunk-oriented processing improves efficiency and transaction management. When a chunk-oriented step begins, it starts a transaction and commits at the end of each chunk.
It’s important to know that there are components called listeners that can be implemented to add logic before or after any action in the process.
Understanding how a job works
A job is composed of one or more steps to be executed. All these executions are saved in Spring Batch’s metadata tables through the JobRepository. Each step can be either chunk-oriented or tasklet-based.
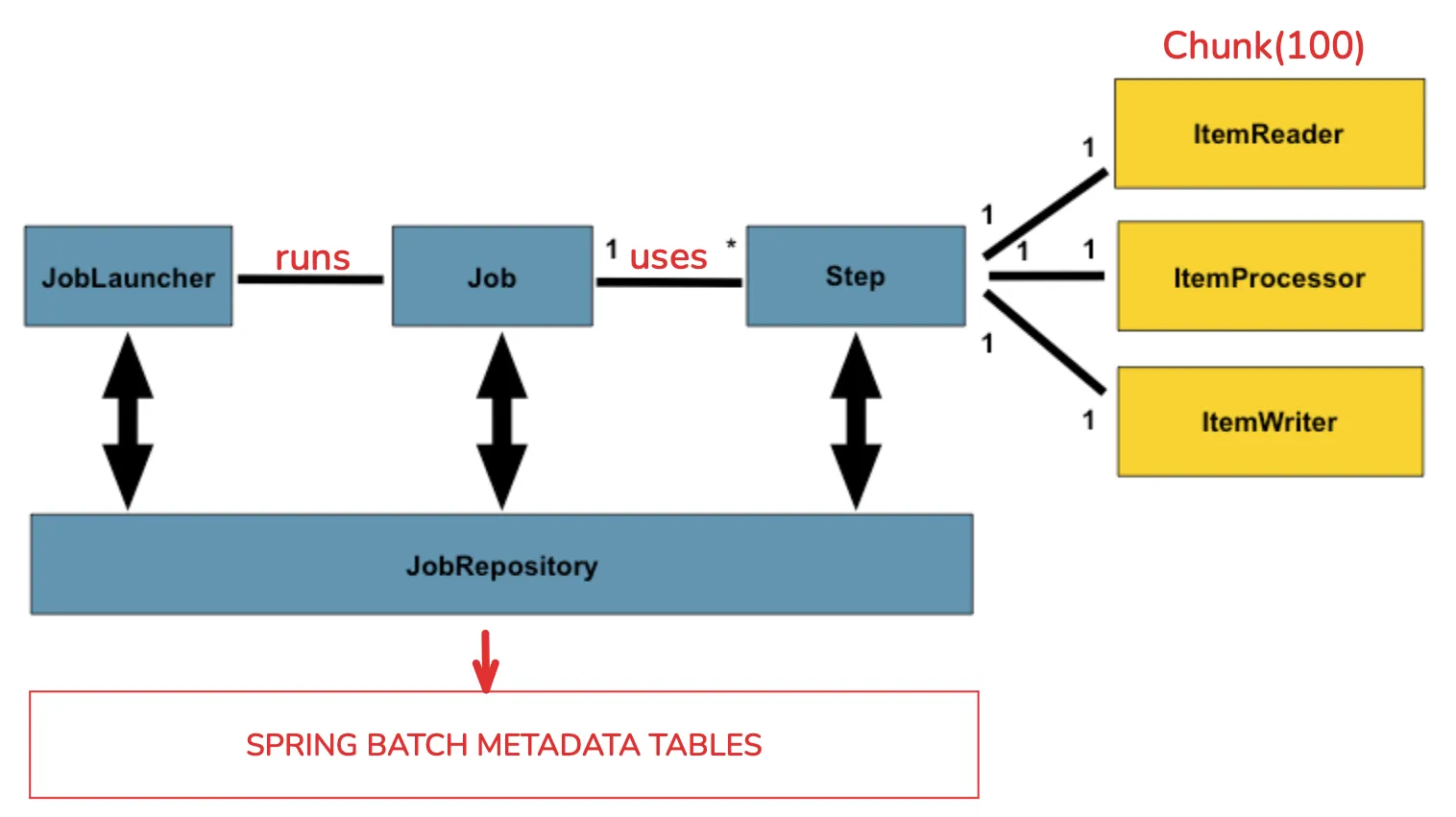
If the step is chunk-oriented, it starts a transaction and commits after each chunk. If an item throws an error, the rollback affects only the current chunk. In these scenarios, we can define retry and/or skip logic for specific exceptions by setting the following options:
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(flatFileItemReader())
.writer(itemWriter())
.faultTolerant()
.skipLimit(10)
.skip(FlatFileParseException.class)
.retryLimit(3)
.retry(DeadlockLoserDataAccessException.class)
.build();
}Now, when the application throws an error of type FlatFileParseException, the execution will not fail until 10 such errors occur. The same applies to the retry logic, but only for the specific exception defined for it.
Observability in Spring Batch
In Spring Batch, it’s possible to implement different types of listeners that are triggered before and after specific actions within the execution flow. Available listeners can be attached at the following levels: Job, Step, Chunk, Skip, Reader, Processor, and Writer.
For jobs, the interface to implement the listener is JobExecutionListener, while for the other components the main interface is StepListener, and each specific implementation provides its own methods like beforeChunk, afterChunk, beforeProcess, afterProcess, among others.
By defining listeners at each of these points and designing proper monitoring and measurement strategies, we can build a highly observable system with detailed insight into every stage of the processing.
When you combine this with the stats stored in Spring Batch’s metadata tables, you get a clear and detailed view of everything your application is doing behind the scenes.

The next step in the Spring Batch world is digging into parallel processing: what you need to consider, common strategies, and some tips to get the most out of your batch jobs. I’ll cover all that in the next article, so stay tuned!