Construyendo una API de alta disponibilidad con Spring Boot y RabbitMQ
Construir una API con Spring Boot que maneje más de 7 millones de peticiones al día es posible sin escalar vertical u horizontalmente.
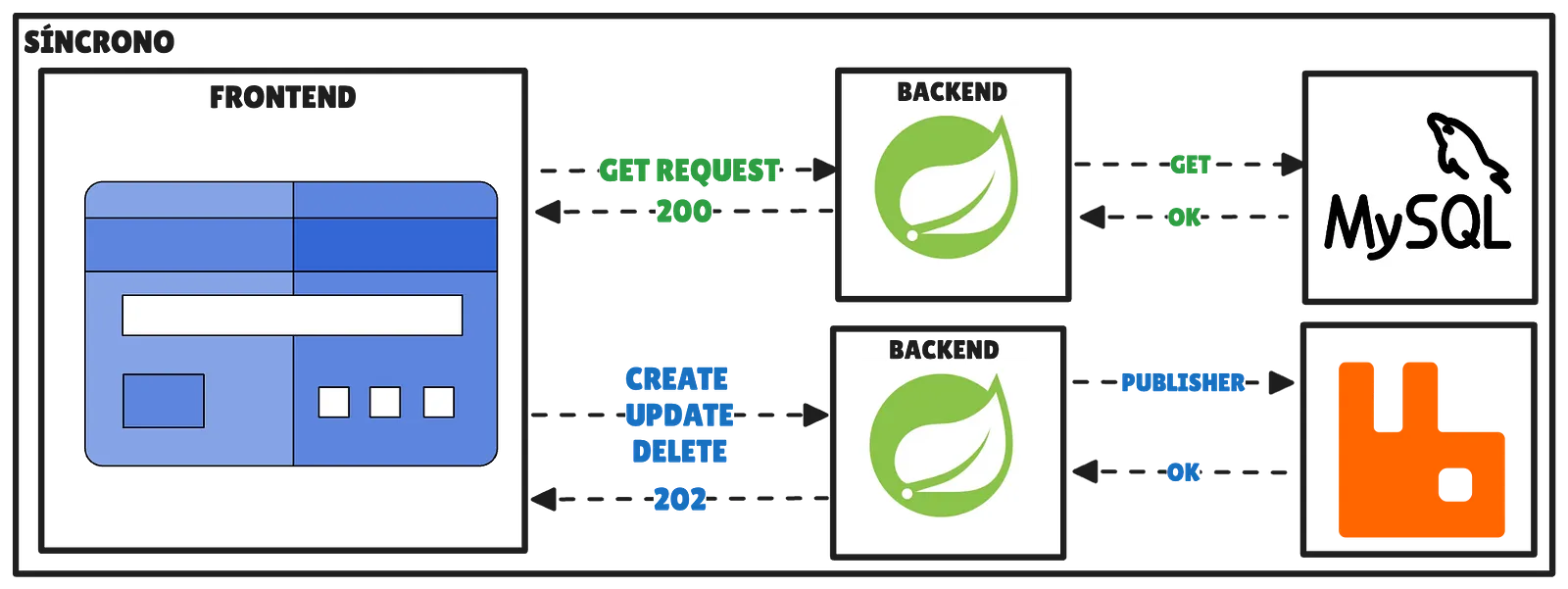
En el mercado es común que una empresa desarrolle un producto sin tener en cuenta la escalabilidad desde el punto de vista del desarrollo, principalmente para evitar la parálisis por sobreanálisis y validar la idea, o por no tener los conocimientos técnicos necesarios en el momento.
Cuando esto sucede, por norma general se llega a una fase donde hay que refactorizar la aplicación para poder escalarla eficientemente y reducir la deuda técnica. Esto se debe a que, más allá de comprar más servidores o mejorar el hardware existente, el coste de oportunidad que puedes obtener al optimizar la arquitectura del software actual es mucho mayor.
Escalabilidad en el software
- Escalar verticalmente: consiste en añadir más recursos al hardware existente: mayor RAM, memoria, etc.
- Escalar horizontalmente: consiste en añadir nuevos servidores. Es la opción más común; se gestionan mediante balanceadores de carga, clústeres de Kubernetes, etc.
Conexiones con la base de datos
Por norma general, el cuello de botella de los sistemas es la base de datos, y depende de las configuraciones y limitaciones de cada una. Esto se debe a que las bases de datos solo permiten una cantidad finita de conexiones para asegurar la integridad de los datos almacenados: podemos tener aproximadamente entre 100 y 150 conexiones en el pool de la base de datos (insisto, depende de cada motor y configuración).
En una red social con millones de usuarios creando publicaciones, comentando e interactuando entre sí, es fundamental garantizar niveles de servicio que aseguren una experiencia de uso fluida.
Para lograrlo existen diversas soluciones a nivel de infraestructura —como el particionamiento de la base de datos o configuraciones de replicación lectura/escritura con sincronización periódica—, aunque todas ellas implican un esfuerzo técnico adicional y un mayor coste en hardware.
Sin embargo, también podemos adoptar estrategias de arquitectura en el desarrollo que permitan ofrecer una API capaz de manejar millones de peticiones sin depender únicamente de la escalabilidad de la base de datos.
- Cacheado de peticiones: implementar sistemas de caché permite responder a muchas solicitudes sin necesidad de acceder a la base de datos principal, reduciendo drásticamente la carga sobre ella y mejorando el tiempo de respuesta.
- Procesamiento asíncrono y en lote: aunque las peticiones GET deben resolverse en tiempo real, no ocurre lo mismo con las operaciones de creación, actualización o eliminación de recursos. Estas pueden procesarse de forma asíncrona. Si, además, agrupamos múltiples operaciones procedentes de distintos usuarios para procesarlas en lote, el número de conexiones necesarias con la base de datos disminuye notablemente, aumentando la eficiencia y la escalabilidad del sistema.
Caso práctico
Escenario: desarrollar una API (CRUD) para la creación de publicaciones y comentarios en una red social con millones de usuarios activos a diario.
Las tecnologías a utilizar son:
- Java
- Spring framework: Boot, Data (Hibernate y JPA)
- RabbitMQ
- MySQL
- Load testing: K6
Esquema general
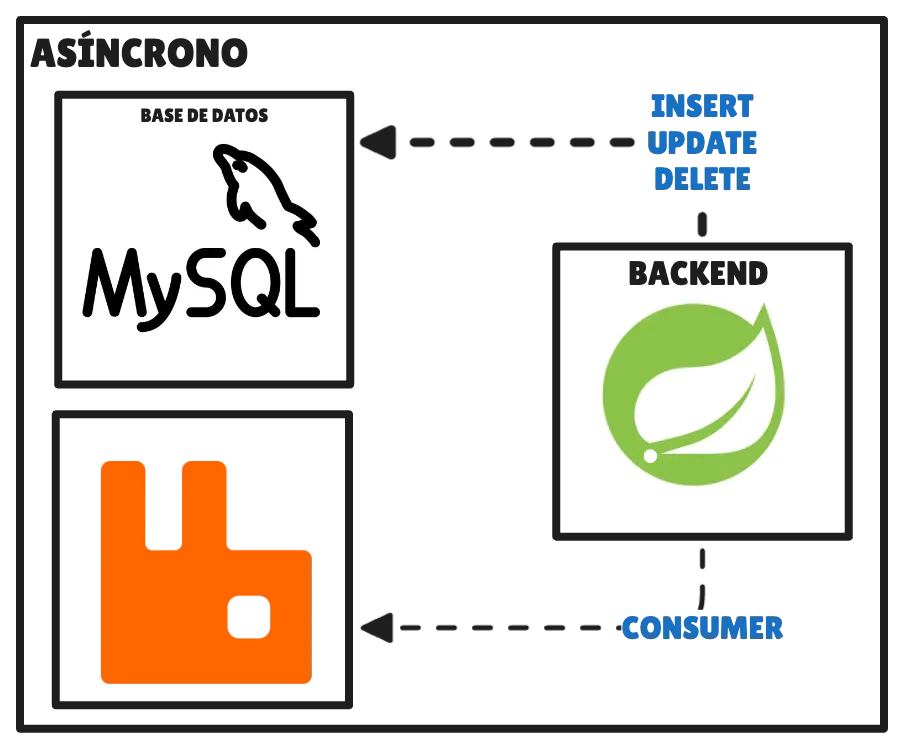
La idea es desarrollar un backend que obtenga los recursos mediante peticiones GET en tiempo real, y que el resto de operaciones más costosas —crear, modificar o eliminar datos— se procesen de forma asíncrona mediante el uso de eventos y una cola.
En Spring esto lo podemos lograr usando RabbitMQ y, para optimizar el uso del pool de conexiones, podemos configurarlo para agrupar X cantidad de eventos cada N segundos y procesarlos en lotes. Vayamos al código.
Configuración de RabbitMQ en lote:
/**
* RabbitMQ batch consumer configuration.
*
* Accumulates messages for up to 1 second or until the batch size is reached,
* then processes them together in a batch. Includes retry handling with a
* maximum of 3 attempts before rejecting the message.
*/
@Configuration
public class BatchRabbitConsumerConfig {
@Bean
public Jackson2JsonMessageConverter jackson2JsonMessageConverter() {
return new Jackson2JsonMessageConverter();
}
@Bean
public SimpleRabbitListenerContainerFactory batchFactory(ConnectionFactory connectionFactory, Jackson2JsonMessageConverter messageConverter) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setMessageConverter(messageConverter);
factory.setBatchListener(true);
factory.setConsumerBatchEnabled(true);
factory.setBatchSize(100);
factory.setReceiveTimeout(1000L);
factory.setConcurrentConsumers(2);
factory.setMaxConcurrentConsumers(8);
factory.setDefaultRequeueRejected(false);
Advice retryInterceptor = RetryInterceptorBuilder.stateless()
.maxAttempts(3)
.recoverer((args, cause) -> {
throw new AmqpRejectAndDontRequeueException("Retry attempts exhausted", cause);
})
.build();
factory.setAdviceChain(retryInterceptor);
return factory;
}
}Con esta configuración le decimos a RabbitMQ que agrupe 100 peticiones cada 1 segundo, con 2 consumidores en paralelo.
El publisher de cada tipo, cuando queremos crear, modificar o eliminar un post:
@Component
public class PostRabbitPublisher implements PostPublisher {
private final RabbitTemplate rabbitTemplate;
private final String rkCreate;
private final String rkUpdate;
private final String rkDelete;
private final String exchange;
public PostRabbitPublisher(
RabbitTemplate rabbitTemplate,
@Value("${rabbit.posts.exchange}") String exchange,
@Value("${rabbit.posts.routing.create}") String rkCreate,
@Value("${rabbit.posts.routing.update}") String rkUpdate,
@Value("${rabbit.posts.routing.delete}") String rkDelete) {
this.rabbitTemplate = rabbitTemplate;
this.exchange = exchange;
this.rkCreate = rkCreate;
this.rkUpdate = rkUpdate;
this.rkDelete = rkDelete;
}
@Override
public UUID createPost(CreatePostRequest request) {
UUID requestId = UUID.randomUUID();
rabbitTemplate.convertAndSend(exchange, rkCreate,
new PostCreateMessage(requestId, request.title(), request.content()));
return requestId;
}
@Override
public UUID updatePost(UpdatePostRequest request) {
UUID requestId = UUID.randomUUID();
rabbitTemplate.convertAndSend(exchange, rkUpdate,
new PostUpdateMessage(requestId, request.id(), request.title(),
request.content(), request.likes()));
return requestId;
}
@Override
public UUID deletePost(DeletePostRequest request) {
Long id = request.id();
UUID requestId = UUID.randomUUID();
rabbitTemplate.convertAndSend(exchange, rkDelete,
new PostDeleteMessage(requestId, id));
return requestId;
}
}Por último, el consumer asociado:
@Component
@RequiredArgsConstructor
@Log4j2
public class PostRabbitConsumer {
private final PostRepository postRepository;
@RabbitListener(queues = "${rabbit.posts.queues.create}", containerFactory = "batchFactory")
public void onCreateBatch(List<PostCreateMessage> batch) {
log.info("Received: '" + batch.size() + "' creation request.");
List<Post> posts = batch.parallelStream().map(request -> Post.builder()
.content(request.content())
.title(request.title())
.build()).toList();
postRepository.saveAll(posts);
}
@RabbitListener(queues = "${rabbit.posts.queues.update}", containerFactory = "batchFactory")
public void onUpdateBatch(List<PostUpdateMessage> batch) {
log.info("Received: '" + batch.size() + "' update request.");
Map<Long, PostUpdateMessage> mapByPostId = batch.stream()
.collect(Collectors.toMap(PostUpdateMessage::id, Function.identity(), (msg1, msg2) -> msg2));
List<Post> posts = postRepository.findAllById(mapByPostId.keySet().stream().toList());
List<Post> postsToUpdate = new ArrayList<>(posts.size());
posts.stream().forEach(post -> {
PostUpdateMessage message = mapByPostId.get(post.getId());
String title = message.title() != null ? message.title() : post.getTitle();
String content = message.content() != null ? message.content() : post.getContent();
Long likes = message.likes() != null ? message.likes() : post.getLikes();
Post postUpdated = post.toBuilder()
.title(title)
.content(content)
.likes(likes)
.lastModifiedDate(OffsetDateTime.now())
.build();
postsToUpdate.add(postUpdated);
});
postRepository.saveAll(postsToUpdate);
}
@RabbitListener(queues = "${rabbit.posts.queues.delete}", containerFactory = "batchFactory")
public void onDeleteBatch(List<PostDeleteMessage> batch) {
log.info("Received: '" + batch.size() + "' delete request.");
List<Long> ids = batch.stream()
.map(PostDeleteMessage::id)
.toList();
postRepository.deleteAllById(ids);
}
}En este punto me gustaría resaltar la forma de hacer las actualizaciones en el método onUpdateBatch: recuperamos primero todos los posts afectados por el lote que estamos procesando, los gestionamos y al final los guardamos en lote de nuevo. Esto hace que tengamos solo 2 interacciones con la base de datos en vez de X interacciones.
Hay muchas otras cosas que podemos mejorar si necesitamos más optimización. Por ejemplo, usé JPA con la propiedad batch_size: 100 activada para gestionar en lote las interacciones con la base de datos, pero si necesitamos más optimización podríamos bajar una capa más y usar JDBC. Al final todo depende de las necesidades del proyecto.
Resultado del test de carga con K6
Haciendo una equivalencia para manejar 7 millones de peticiones, realicé un test de carga a la API en local con K6. Los resultados fueron más que satisfactorios:
/\ Grafana /‾‾/
/\ / \ |\ __ / /
/ \/ \ | |/ / / ‾‾\
/ \ | ( | (‾) |
/ __________ \ |_|\_\ \_____/
execution: local
script: load-testing/perf-posts-comments.js
output: -
scenarios: (100.00%) 8 scenarios, 591 max VUs, 3m15s max duration (incl. graceful stop):
* create_posts: 120.00 iterations/s for 2m0s (maxVUs: 120-240, exec: createPostCommand, gracefulStop: 30s)
* query_posts: 60.00 iterations/s for 2m0s (maxVUs: 60-120, exec: listPosts, gracefulStop: 30s)
* create_comments: 25.00 iterations/s for 2m0s (maxVUs: 25-50, exec: createCommentCommand, startTime: 5s, gracefulStop: 30s)
* query_comments: 30.00 iterations/s for 2m0s (maxVUs: 30-60, exec: listComments, startTime: 10s, gracefulStop: 30s)
* update_posts: 36.00 iterations/s for 2m0s (maxVUs: 36-72, exec: updatePostCommand, startTime: 15s, gracefulStop: 30s)
* delete_posts: 12.00 iterations/s for 2m0s (maxVUs: 12-24, exec: deletePostCommand, startTime: 25s, gracefulStop: 30s)
* update_comments: 8.00 iterations/s for 2m0s (maxVUs: 8-15, exec: updateCommentCommand, startTime: 35s, gracefulStop: 30s)
* delete_comments: 3.00 iterations/s for 2m0s (maxVUs: 3-10, exec: deleteCommentCommand, startTime: 45s, gracefulStop: 30s)
█ TOTAL RESULTS
checks_total.......: 28203 170.91221/s
checks_succeeded...: 100.00% 28203 out of 28203
checks_failed......: 0.00% 0 out of 28203
HTTP
http_req_duration..............: avg=4.41ms min=66µs med=556µs max=143.29ms p(90)=12.69ms p(95)=15.49ms
{ expected_response:true }...: avg=4.41ms min=66µs med=556µs max=143.29ms p(90)=12.69ms p(95)=15.49ms
http_req_failed................: 0.00% 0 out of 46331
http_reqs......................: 46331 280.769194/s
EXECUTION
iteration_duration.............: avg=5.89ms min=102.37µs med=2.81ms max=146.48ms p(90)=14.12ms p(95)=17.06ms
iterations.....................: 35286 213.835699/s
vus............................: 0 min=0 max=8
vus_max........................: 294 min=294 max=294
NETWORK
data_received..................: 189 MB 1.1 MB/s
data_sent......................: 7.6 MB 46 kB/sConclusiones
No es una solución definitiva ni aplicable al 100% de los casos. Procesar asíncronamente estas peticiones obliga también a desarrollar ciertas lógicas en el frontend, y pueden darse casos en los que se tarde más en procesar según qué solicitud. Lo más correcto sería desarrollar un sistema que consulte el estado de la petición del usuario en caso de que el frontend quiera recargar inmediatamente el dato; esto puede complicar el proyecto del frontend, aunque da un mayor control y fiabilidad de lo que sucede en nuestro sistema.
El uso de colas también puede dar lugar a tener que desarrollar una gestión de errores de las colas donde se almacenan los reintentos fallidos. Por un lado, esto puede implicar una complicación de la arquitectura del proyecto, pero también nos da una mayor trazabilidad y control de lo que sucede en nuestro sistema.
Puedes ver el código completo en el repositorio.
¿Se te ocurren otras prácticas que mejoren el funcionamiento de un sistema con miles de millones de peticiones?