Notes app — CQRS: separar lectura y escritura
Un tema muy importante en el desarrollo de software es el escalado de las aplicaciones, que suele volverse un dolor de cabeza al mantener proyectos.
Entre los problemas más comunes suelen destacar los que aparecen entre el servidor backend y la base de datos, ya sea porque se agotan las conexiones, por inconsistencias de datos ante peticiones masivas, entre otros. Imaginemos un caso práctico:
Tenemos un proceso que mantiene 2 segundos la conexión con la base de datos cuando se lanza sobre el mismo conjunto de datos. Nuestra base de datos solo tiene 10 conexiones disponibles, pero 11 usuarios necesitan acceder al mismo tiempo a dicho proceso: el undécimo usuario no podrá acceder a los datos porque las conexiones están ocupadas.
Por norma general, esta situación se resolverá cuando el undécimo usuario vuelva a intentarlo y haya terminado el proceso de alguno de los 10 anteriores.
Pero ¿y si hablamos de 100 usuarios? ¿Qué puede fallar? El servidor va a intentar conectarse 90 veces de forma fallida a la base de datos, lo que terminará dando un error: ya sea por un timeout de la conexión o por sobrecargar la memoria, ya que por cada uno de esos intentos reintentará conectarse varias veces si hay algún sistema de reintento cacheando las peticiones.
Hay muchas formas de resolver esto. Una es introducir un sistema de cacheado de peticiones a la base de datos, de modo que solo el primer usuario haga la petición y a los siguientes 99 se les devuelva el resultado almacenado en caché, aunque esto no siempre es viable.
Otra solución es establecer configuraciones muy robustas para que el servidor no ahogue la base de datos, aunque dejarías sin servicio a 90 usuarios o más, dependiendo de la cantidad que acceda al recurso.
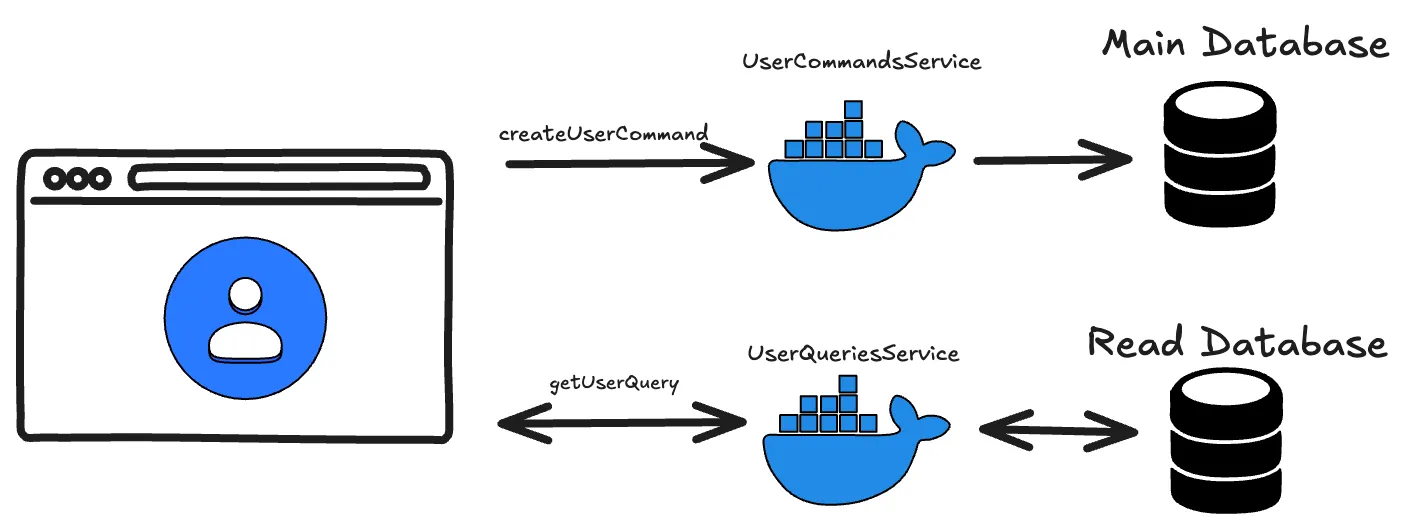
En este artículo abordaremos el problema con el patrón CQRS, que consiste en separar las operaciones de lectura y escritura sobre la base de datos a nivel de desarrollo.
Lo ideal sería incluso separar los servidores, de forma que uno se encargue de las operaciones de lectura y otro de las de escritura, pero aquí lo veremos en conjunto en el ejemplo.
Lo primero es responder a cómo esto resuelve los problemas de escalado mencionados, porque requiere una estrategia más elaborada que aplicar un patrón mágico:
- Tendremos una instancia de base de datos principal, donde se ejecutarán todas las operaciones de escritura, para evitar inconsistencias de datos.
- Crearemos otras bases de datos de solo lectura según necesitemos, que serán réplicas de la principal y donde irán todas las operaciones de lectura.
De esta forma no tenemos que escalar verticalmente de forma infinita nuestra base de datos principal, y repartimos la carga al discriminar las operaciones.
Código
Nuestro ejemplo tendrá dos casos: obtener la información de un usuario a partir de un nombre de usuario, y eliminar un usuario. Veamos el de obtener la información.
Primero definimos nuestra query:
public class GetUserQuery {
private String username;
private GetUserQuery(Builder builder) {
this.username = builder.username;
}
public String getUsername() {
return username;
}
public static Builder builder() {
return new Builder();
}
public static class Builder {
private String username;
public Builder username(String username) {
if (username == null || username.isEmpty()) {
throw new IllegalArgumentException("username cannot be null");
}
this.username = username;
return this;
}
public GetUserQuery build() {
return new GetUserQuery(this);
}
}
}Creamos el controlador que gestionará las queries de usuarios:
@RestController
@RequestMapping("/user/queries")
@RequiredArgsConstructor
public class UserQueriesController {
private final UserQueryHandler queryHandler;
@GetMapping("{username}")
public ResponseEntity<User> getUserByUsername(
@PathVariable String username
) {
GetUserQuery getUserQuery = GetUserQuery.builder()
.username(username)
.build();
User user = queryHandler.handle(getUserQuery);
return ResponseEntity.ok().body(user);
}
}Definimos la interfaz del handler:
public interface UserQueryHandler {
User handle(GetUserQuery getUserQuery);
}E implementamos la interfaz en nuestro servicio, gestionando la lógica para buscar el usuario:
@Service
@RequiredArgsConstructor
public class UserService implements UserQueryHandler {
private final UserRepository userRepository;
@Override
public User handle(GetUserQuery query) {
return userRepository.findById(query.getUsername())
.map(userEntity -> User.builder()
.username(userEntity.username())
.email(userEntity.email())
.build())
.orElseThrow(() -> new RuntimeException("User not found"));
}
}Conclusión
Mediante este patrón podemos separar las operaciones de lectura y escritura de nuestros proyectos, lo que nos permite implementar estrategias de escalado horizontal.
Esto se debe a que, si nuestras aplicaciones reciben más peticiones de lectura que de escritura, podemos gestionar diferentes instancias y diferentes bases de datos de lectura sin tener que escalar verticalmente una única base de datos.
Como todas las soluciones, tiene sus pros y sus contras. Ya hemos hablado de los beneficios; como desventaja, tendremos que mantener varias bases de datos y varias instancias (las de lectura y las de escritura), por lo que añadimos cierta complejidad al sistema.
Si quieres ver el progreso del proyecto, puedes acceder al repositorio aquí.