Spring Batch — Consejos prácticos para jobs de datos robustos y rápidos

En un artículo anterior hablé de Spring Batch. Si no lo has leído y no conoces Spring Batch, te recomiendo leerlo aquí primero.
En este post vamos a hablar de cómo mejorar el rendimiento y el escalado en Spring Batch. Me gustaría centrarme en dos temas:
- Ejecución en paralelo.
- Consideraciones de memoria y base de datos a tener en cuenta al desarrollar una aplicación batch.
Ejecuciones en paralelo
Hay dos tipos de ejecuciones en paralelo en Spring Batch:
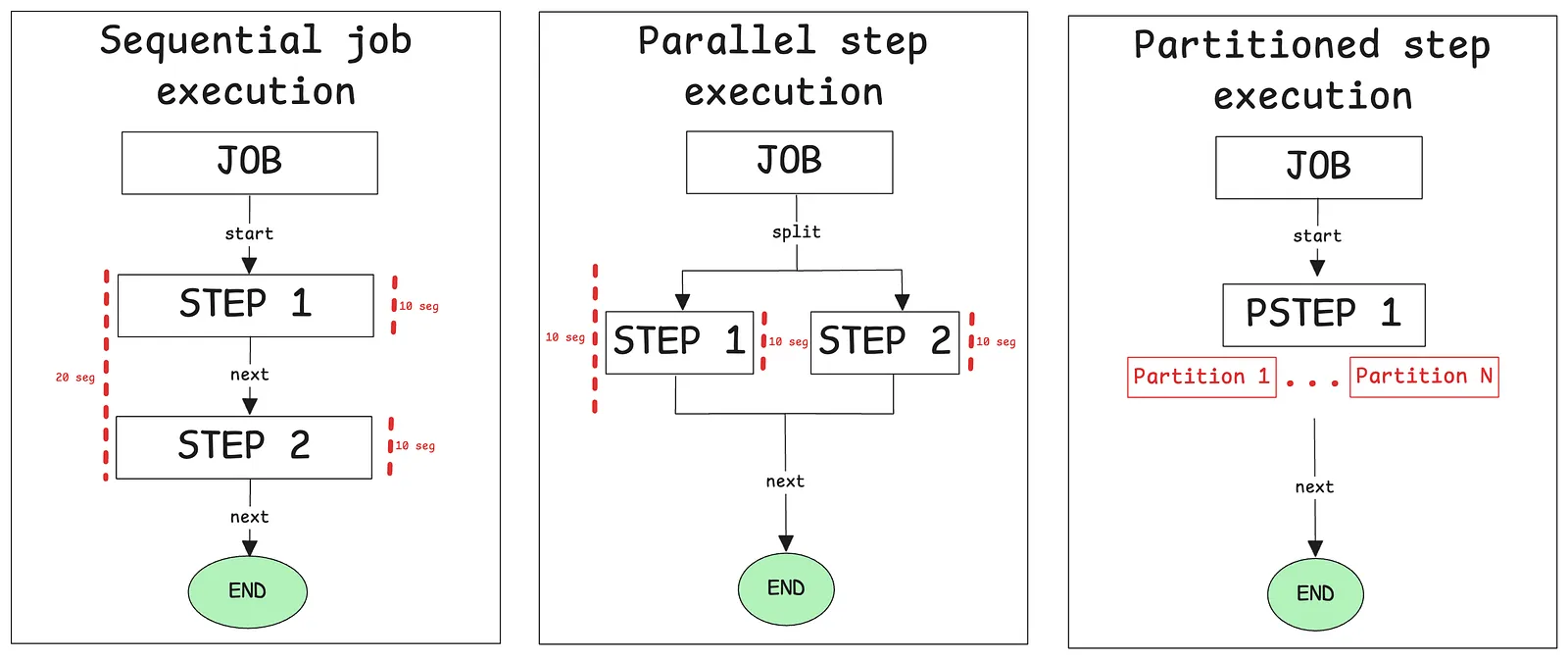
- Flujo en paralelo de ejecuciones de steps.
- Particionado de un step.
Flujo en paralelo de ejecuciones de steps
Escenario: estamos en la junta directiva del FC Barcelona y, para mejorar las estadísticas del equipo, necesitamos calcular distintos KPI que no dependen entre sí. Calculemos: 🥅 goles, 🎯 pases, 🟥 tarjetas.
@Bean
public TaskExecutor taskExecutor() {
// No recomendable en entornos de producción
return new SimpleAsyncTaskExecutor("spring_batch");
}
@Bean
public Job job() {
return new JobBuilder("job", jobRepository)
.start(calculateKpisFlow())
.next(sendEmailStep()).build()
.build();
}
@Bean
public Flow calculateKpisFlow() {
return new FlowBuilder<SimpleFlow>("calculateKpisFlow")
.split(taskExecutor())
.add(goalsFlow(), passesFlow(), cardsFlow())
.build();
}
@Bean
public Flow goalsFlow() {
return new FlowBuilder<SimpleFlow>("goalsFlow")
.start(goalsStep())
.build();
}
@Bean
public Step goalsStep() {
return new StepBuilder("goalsStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("Calculating goals...");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
@Bean
public Flow passesFlow() {
return new FlowBuilder<SimpleFlow>("passesFlow")
.start(passesStep())
.build();
}
@Bean
public Step passesStep() {
return new StepBuilder("passesStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("Calculating passes...");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
@Bean
public Flow cardsFlow() {
return new FlowBuilder<SimpleFlow>("cardsFlow")
.start(cardsStep())
.build();
}
@Bean
public Step cardsStep() {
return new StepBuilder("cardsStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("Calculating cards...");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
@Bean
public Step sendEmailStep() {
return new StepBuilder("sendEmailStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("Sending email...");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}Con esta configuración vamos a ejecutar cada flow —goalsFlow(), passesFlow(), cardsFlow()— en paralelo. En Java 21+ podemos usar virtual threads con el task executor llamando al método setVirtualThreads(true).
Particionado de un step
Escenario: tenemos un gran número de pases en nuestras estadísticas y passesStep() tarda demasiado en ejecutarse. Necesitamos particionarlo para mejorar el rendimiento.
@Bean
public Step passesStep() {
return new StepBuilder("passesStep", jobRepository)
.partitioner("passesSlaveStep", passesPartitioner)
.step(passesSlaveStep())
.gridSize(3) // Número de particiones para los pases
.taskExecutor(taskExecutor())
.allowStartIfComplete(true)
.build();
}
@Bean
public Step passesSlaveStep() {
return new StepBuilder("passesSlaveStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
List<String> passes = (List<String>) chunkContext.getStepContext().getStepExecution()
.getExecutionContext().get("passes");
String stepName = chunkContext.getStepContext().getStepName();
log.info("In step: " + stepName + ", " + passes.size() + " passes are being processed");
return RepeatStatus.FINISHED;
}, transactionManager)
.allowStartIfComplete(true)
.build();
}Necesitamos crear un Partitioner que implemente la lógica para particionar los datos que procesarán los slave workers:
@Component
public class PassesPartitioner implements Partitioner {
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
List<String> passes = Arrays.asList(
"Short pass - Madrid vs Barcelona",
"Long pass - Real Sociedad vs Athletic",
"Through pass - Valencia vs Sevilla",
"Lateral pass - Atlético vs Villarreal",
"Filtered pass - Betis vs Osasuna",
"One-touch pass - Getafe vs Mallorca",
"Cross pass - Cádiz vs Almería",
"Lob pass - Girona vs Las Palmas");
Map<String, ExecutionContext> partitions = new HashMap<>();
int totalItems = passes.size();
int itemsPerPartition = (int) Math.ceil((double) totalItems / gridSize);
for (int i = 0; i < gridSize; i++) {
int startIndex = i * itemsPerPartition;
int endIndex = Math.min(startIndex + itemsPerPartition, totalItems);
if (startIndex < totalItems) {
ExecutionContext context = new ExecutionContext();
List<String> partitionPasses = new ArrayList<>(passes.subList(startIndex, endIndex));
context.put("passes", partitionPasses);
partitions.put("partition" + i, context);
}
}
return partitions;
}
}Ahora podemos revisar nuestros logs y ver cómo este step se ejecuta en paralelo:
2025-06-05T01:06:31.589+01:00 INFO 70998 --- [demo] [ spring_batch3] o.s.batch.core.job.SimpleStepHandler : Executing step: [cardsStep]
2025-06-05T01:06:31.589+01:00 INFO 70998 --- [demo] [ spring_batch2] o.s.batch.core.job.SimpleStepHandler : Executing step: [passesStep]
Calculating cards...
2025-06-05T01:06:31.597+01:00 INFO 70998 --- [demo] [ spring_batch3] o.s.batch.core.step.AbstractStep : Step: [cardsStep] executed in 7ms
2025-06-05T01:06:31.608+01:00 INFO 70998 --- [demo] [ spring_batch5] com.example.demo.jobs.DemoJob : In step: passesSlaveStep:partition2, 2 passes are being processed
2025-06-05T01:06:31.608+01:00 INFO 70998 --- [demo] [ spring_batch4] com.example.demo.jobs.DemoJob : In step: passesSlaveStep:partition0, 3 passes are being processed
2025-06-05T01:06:31.609+01:00 INFO 70998 --- [demo] [ spring_batch6] com.example.demo.jobs.DemoJob : In step: passesSlaveStep:partition1, 3 passes are being processed
2025-06-05T01:06:31.610+01:00 INFO 70998 --- [demo] [ spring_batch5] o.s.batch.core.step.AbstractStep : Step: [passesSlaveStep:partition2] executed in 4ms
2025-06-05T01:06:31.611+01:00 INFO 70998 --- [demo] [ spring_batch4] o.s.batch.core.step.AbstractStep : Step: [passesSlaveStep:partition0] executed in 4ms
2025-06-05T01:06:31.612+01:00 INFO 70998 --- [demo] [ spring_batch6] o.s.batch.core.step.AbstractStep : Step: [passesSlaveStep:partition1] executed in 5ms
2025-06-05T01:06:31.615+01:00 INFO 70998 --- [demo] [ spring_batch2] o.s.batch.core.step.AbstractStep : Step: [passesStep] executed in 25msMemoria y base de datos
Muy bien, ya sabemos cómo optimizar aplicaciones Spring Batch, pero siempre hay un cuello de botella que gestionar —sobre todo cuando hablamos de operaciones masivas: la base de datos.
Sabiendo esto, tenemos que ser muy precisos con nuestras configuraciones y código para conseguir un buen rendimiento y prevenir problemas de memoria en nuestra aplicación, como quedarnos sin espacio en el heap y provocar que la aplicación caiga.
Memoria heap
Cuando desarrollas una aplicación orientada a datos, tienes que tener en cuenta cuántos datos vas a procesar. Si tienes 1 millón de registros y haces algo como esto:
List<Object> oneMillionObjects = readOneMillionObjects();
List<Object> oneMillionObjectsProcessed = processThis(oneMillionObjects);Ahora tienes 2 millones de objetos en tu heap. Digamos que tu objeto es así:
public record Object(
long id, // 8 bytes
String name, // 4 + 12 + 4 + 4 + 1 + 1 + tamaño del string = 26+ bytes
String description // 4 + 12 + 4 + 4 + 1 + 1 + tamaño del string = 26+ bytes
) { }Desglose del uso de memoria por campo. En Java, cada objeto String tiene:
- Cabecera del String: ~12 bytes
- Referencia al
byte[]: 4 bytes - Hash: 4 bytes
- Coder (Java 9+): 1 byte
- Padding: 1 byte
Ahora:
longes un primitivo: 8 bytesStringes un objeto: ~22 bytes + el tamaño real del string- No olvides que la propia instancia del objeto añade ~22 bytes
Así que, para un objeto como new Object(1L, "John Doe", "Example text description to this object"), estás usando aproximadamente 168 bytes por instancia. Si tienes 1 millón: 1M × 168 bytes = ~160 MB. Con dos listas (la original + la procesada), estás reteniendo ~320 MB en memoria heap —sin ninguna necesidad real.
Buena práctica en apps batch: en las aplicaciones batch tenemos que ser conscientes de estas situaciones y procesar los items sin mantenerlos en memoria. Si podemos usar primitivos o evitar colecciones innecesarias, mejor todavía:
readOneMillionObjects().stream().forEach(object -> {
processThis(object);
});Y ya está. Incluso podrías usar parallelStream() para acelerarlo —pero cuidado: tu método processThis() debe ser thread-safe, o te toparás con problemas de concurrencia como condiciones de carrera o errores de fork.
Base de datos
Otra cosa importante a tener en cuenta es el pool de conexiones a la base de datos. Para garantizar la eficiencia del procesamiento de datos tenemos que aplicar una configuración específica según el tamaño del flujo de datos que vayamos a manejar.
Recomiendo encarecidamente leer las propiedades de HikariCP en la documentación del repositorio de HikariCP. Pero si no quieres, aquí va el resumen:
Aunque configures maximumPoolSize a 5000, lo más probable es que tu app sea más lenta que si lo pones a 100. ¿Por qué? Por principios básicos de informática.
Si tienes 12 procesadores e intentas ejecutar 5000 hilos en paralelo, cada procesador acaba gestionando alrededor de 416 hilos. Funciona así:
procesador: 1
START THREAD 1
PAUSE THREAD 1
START THREAD 2
PAUSE THREAD 2
CONTINUE THREAD 1
PAUSE THREAD 1
START THREAD 3
PAUSE THREAD 3
START THREAD 4
PAUSE THREAD 4Todo ese cambio de contexto (arrancar, pausar, reanudar hilos) introduce overhead y hace el sistema más lento. En muchos casos es de hecho más rápido ejecutar menos tareas de forma secuencial que sobrecargar el sistema con miles de hilos que solo pasan el tiempo esperando CPU.
ORM vs SQL nativo
Además, cuando escribimos queries SQL o métodos JPA, tenemos que optimizar cada query para conseguir mejor rendimiento. Depende mucho de tus prioridades:
- La comodidad y abstracción de JPA, o
- El rendimiento puro de las queries SQL nativas.
A veces, si manejas un gran volumen de datos, JPA simplemente no es una opción válida —puede que no sea capaz de garantizar el nivel mínimo de velocidad requerido. Recuerda también no complicar tus queries en exceso; es mejor tener steps pequeños y atómicos que queries enormes e inmantenibles.
En esos casos, las queries nativas te dan más control y a menudo resultan en un rendimiento bastante mejor.
Espero que estos consejos te ayuden a desarrollar una aplicación eficiente y robusta con Spring Batch. No dudes en profundizar en la documentación y experimentar con distintas configuraciones —es la mejor forma de entender de verdad cómo se comporta en escenarios reales. ¡Suerte y feliz código!